

STATS
& THOUGHTS
Step-by-step guides on statistical approaches, the papers published which led me to them, and other problems that made me angry.

Screen time isn't the problem for teens: Findings from a 3-year study of 18 schools
A (brief) overview of my dissertation, The Digital Exchange of Human and Social Capital Over Adolescence, published for the completion of my Ph.D. in Information and Media (Michigan State University, 2026).

Interview: Michigan State study shows screen time can boost academic achievement
A couple weeks back I did a LIVE interview with Local 4 Detroit News about a paper myself and Dr. Keith Hampton published in Information, Communication & Society in June (2025) about adolescent screen time, academic achievement, and digital skills (find the full-text here or, for a brief overview, see my blog post here).

Rethinking “screen time”: How online play boosts students’ academic skills
Conversations about adolescent “screen time” often start and end with worry: time online must be stealing attention from school. Our new study asks a different question: What if some of that unstructured time on social media, video games, and general web browsing builds skills that help students do better in school?
When avatars shape us: VR makes the “Proteus effect” stronger
Synthesizing fifty-six experimental studies of the “Proteus effect” (meta-analysis), we examined what conditions make the proteus effect stronger rather than whether or not it exists. The cautious answer: the Proteus effect is robust but probably a bit smaller than headline estimates, and still stronger in VR.
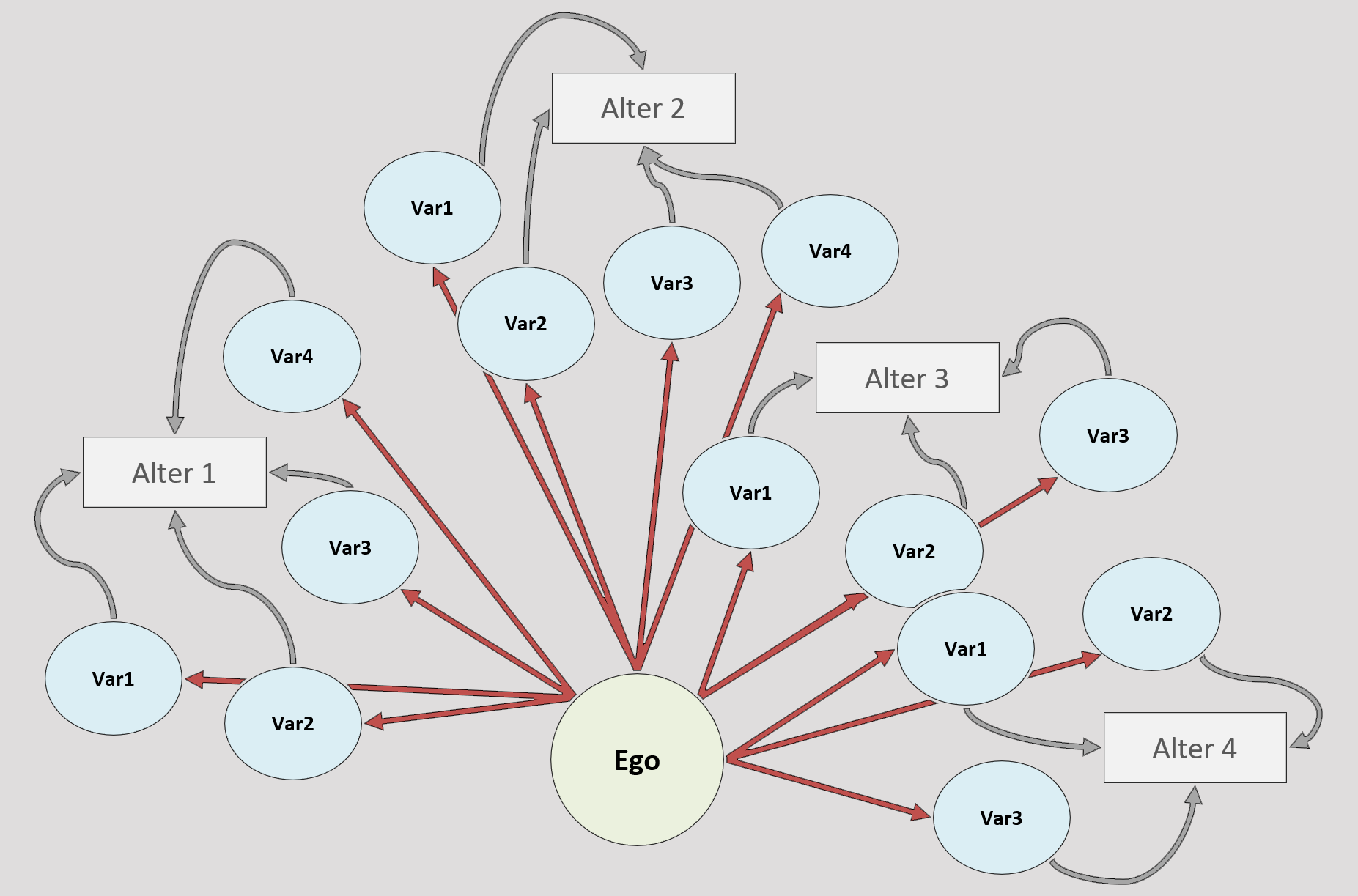
How to analyze alter-level attributes within egocentric network data using SPSS
This write-up adds a much-needed update to Muller et al.’s (1999), “how to use SPSS to study ego-centered networks” by reviewing the process of restructuring and transposing name generator survey data in SPSS.

Report: Gaps in students’ broadband and achievement across the pandemic
An overview of our study assessing the impact of the COVID-19 pandemic on home Internet connectivity, student achievement, and adolescent well-being for students across 18 schools, surveyed in 2019 to 2022. The focus is on middle and high school students enrolled in rural and small-town schools.